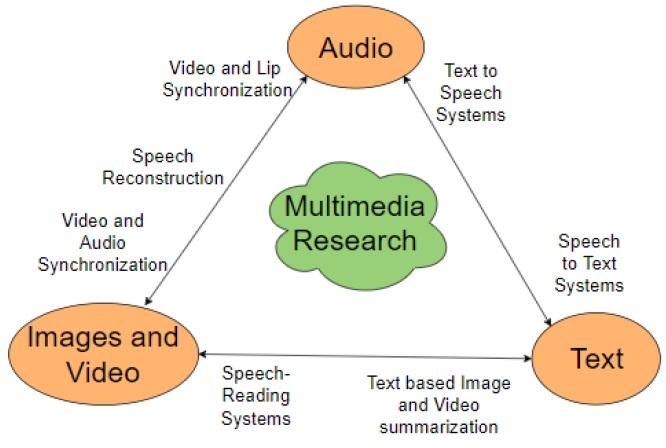
Speechreading broadly involves looking, perceiving, and interpreting spoken symbols. It has a wide range of multimedia applications, such as surveillance, Internet telephony, and as an aid to a person with hearing impairments. However, most of the work in speechreading has been limited to text generation from silent videos. Recently, research has ventured into generating (audio) speech from silent video sequences but there have been no developments in using multiple cameras for speech generation. To this end, this project encompasses the boundaries of multimedia research by putting forth a model which leverages silent video feeds from multiple cameras recording the same subject to generate intelligent speech for a speaker. Initial results confirm the usefulness of exploiting multiple views in building an efficient speech reading and reconstruction system. It further shows the optimal placement of cameras which would lead to the maximum intelligibility of speech. At MIDAS@IIITD, we plan to leverage the proposed system in various innovative applications and focus on its potential prodigious impact in not just security arena but in many other multimedia analytics problems. Our recent paper on speech reconstruction from silent videos is published in ACM Multimedia, a premier Multimedia conference.