This blog is about our research project where we studied abuse and offense detection in the code switched pair of Hindi and English(i.e., Hinglish) under the expert guidance of Dr. Rajiv Ratn Shah, Dr. Roger Zimmermann, and Dr. Ponnurangam Kumaraguru.
As we write this blog, we remember our journey as research interns at MIDAS Lab. We started this project as our college project in August ’18 when this idea was like a small seed which was sown by our friend Yaman Kumar who is experienced in this field. He introduced us with the highly intellectual professors at MIDAS Lab, who not only gave us a direction but also galvanized us each day into transforming this small idea into a full-fledged research project. As we started working, we became cognizant of the fact that it this a vital issue in today’s world and must be addressed. From what we discovered in our journey; we would like to give everyone a glimpse of it - A small idea that turned into a publication in one of the most prestigious conference of Artificial Intelligence - AAAI’19 at Honolulu, Hawaii, USA, as part of the student abstract and poster track.
Why Hinglish(code switched pair of Hindi and English) ?
In the Indian Subcontinent the number of Internet users has been continuously rising with the penetration of internet among the masses.It is being estimated that the number of internet users in India will cross 700 million by 2021.With about 53% of the users using Hinglish as the medium of communication on social media in India, the need of the the hour is to have some system to detect hate speech,offensive and abusive posts on social media.
Has it been done before?
Although there are many previous works which deal with Hindi and English hate speech (the top two languages in India), but very few on the code-switched version (Hinglish) of the two (Mathur et al. 2018). This is partially due to the following reasons:
- Hinglish consists of no-fixed grammar and vocabulary. It derives a part of its semantics from Devnagari and another part from the Roman script.
- Hinglish speech and written text consists of a concoction of words spoken in Hindi as well as English, but written in the Roman script. This makes the spellings variable and dependent on the writer of the text.
Hence code-switched languages present tough challenges in terms of parsing and getting the meaning out of the text.
Our contribution!
Our work primarily consists of these steps: Preprocessing of the dataset, training of word embeddings,training of the classifier model and then using that on HEOT dataset. Preprocessing involves transliteration using Indic-transliteration python library and translation using Xlit-crowd conversion dictionary which was manually added with common Hinglish words and some profane words. This was followed by training of Glove(Pennington, Socher, and Manning 2014) and Twitter word2vec(Godin et al. 2015) embeddings on both the Davidson and HEOT dataset.Finally a ternary classification model was used using LSTM to classify these tweets into three categories(offensive, abusive and benign).
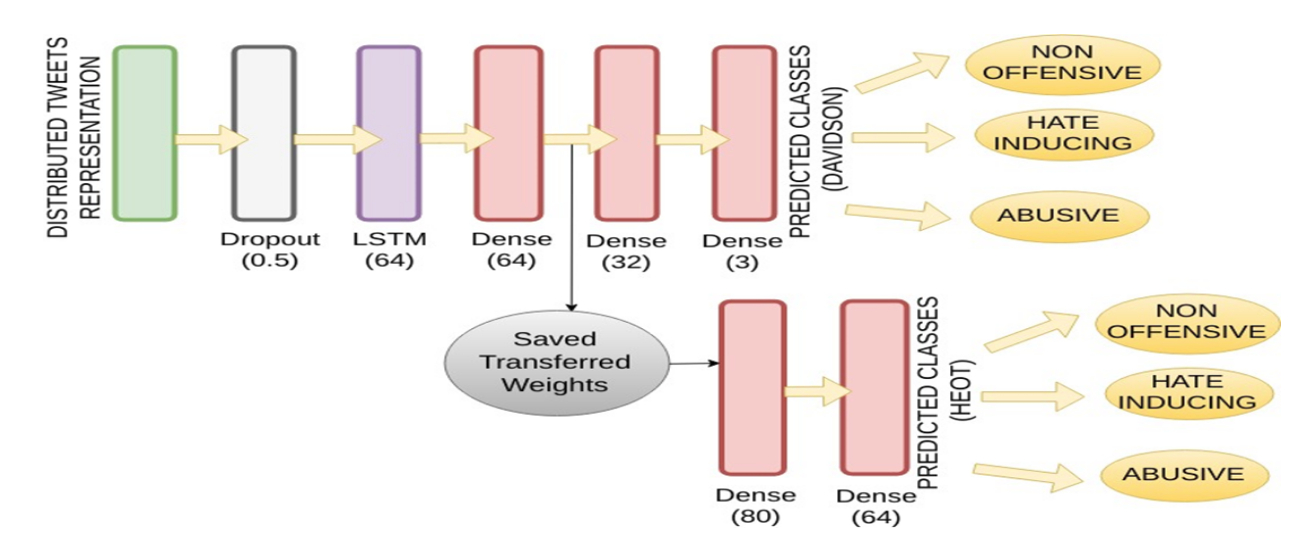
As shown in the above figure the model was initially trained on the dataset provided by Davidson and then re-trained on the HEOT dataset so as to benefit from the transfer of learned features in the last stage.
Results
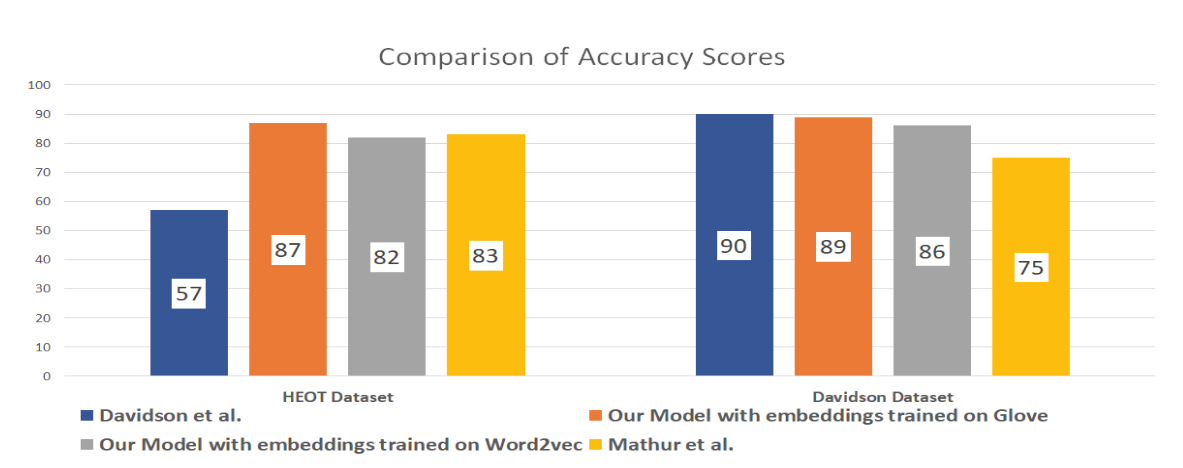 We have produced “state of the art” results for english.Our model trained on Glove embeddings gives the best results on HEOT dataset. For comparison purposes we also calculate the results of our model on the Davidson dataset.
We have produced “state of the art” results for english.Our model trained on Glove embeddings gives the best results on HEOT dataset. For comparison purposes we also calculate the results of our model on the Davidson dataset.
Applications
- Detect False Propaganda by Political Groups in Elections.
- Youtube/Netflix Subtitles – “Auto-beep” offensive language.
- Online Social Media - Report Defamatory Pages and comments.
- Feedback analytics for better user experience.
- Real time “clean-chat” facility.
- Censor board – Auto-eliminate abusive content
Future Work
In future we look to extend the work in the following ways:
Use dependency based word embeddings and compare them to the normal word embeddings.
Work on a model to classify images and videos(also having hindi text) into three categories offensive, abusive and benign.
Detect and report facebook users and pages based on their recent posts.
We feel immensely proud to be the part of this extremely enjoyable journey where we not only learnt just theoretically but also implemented those concepts to real life applications to witness the great impact that technology and artificial intelligence brings to life. We feel honoured and grateful on being able to contribute our skills and simultaneously learn each day from our guides and professors at MIDAS Lab who inspired us throughout the project. This has been a totally satisfying and rewarding experience and would wish to work with the team in future as well to use technology for a better tomorrow. Also, we would like to thank Puneet Mathur for sharing the HEOT dataset and inspiring us through his work in the following paper “Mathur, P.; Shah, R.; Sawhney, R.; and Mahata, D. 2018. Detecting offensive tweets in hindi-english code-switched language. In Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, 18–26.”
Above all, we thank Almighty God for giving us this opportunity, being with us and guiding us in all situations and making our way through each and every problem.
Here is a link to a short video for better understanding of the project - https://drive.google.com/open?id=1rpEcsv03B1yifjLftllK3Hep-Ecyzew2